I’ve been reading a Google paper titled “Agentic AI and the next intelligence explosion.” In it, they suggest that frontier reasoning models (like DeepSeek-R1 and QwQ-32B) don’t improve simply through increased computation time. Instead, they claim these models simulate a “society of thought”—essentially an internal, spontaneous debate between different cognitive perspectives. While those findings would be ground-breaking if accurate, I suspect the authors might be misinterpreting the mechanism.
My own explanation is a bit more grounded. I view an LLM less like a pinpoint search engine and more like a “weighted mesh” of terms (synonyms, antonyms, etc.) that represent clusters of meaning. In this view, the correlation to meaning provides the “intelligence,” while the weighting scheme handles the logic. This creates a system that is logically precise but remains conceptually unaware (no cognitive capability).
Essentially, the LLM identifies language snippets that correlate to meanings within its training set and uses logic to stitch these snippets together into new or existing combinations. Because it operates on this “mesh” principle, it can easily swap one snippet for an equivalent one (re-wording).
Rather than building from primitive symbols or phonetics, the AI is working at a much higher, more efficient level by assembling nearly complete, pre-formed parts. To use an analogy: it’s the difference between building a vehicle from high-level components (as in Scrapheap Challenge) versus smelting iron ore to start from scratch. It’s similar to the debate in evolutionary biology: the gap between DNA base pairs (CATG) is massive, whereas the evolutionary “gap” between languages like French and German is relatively small.
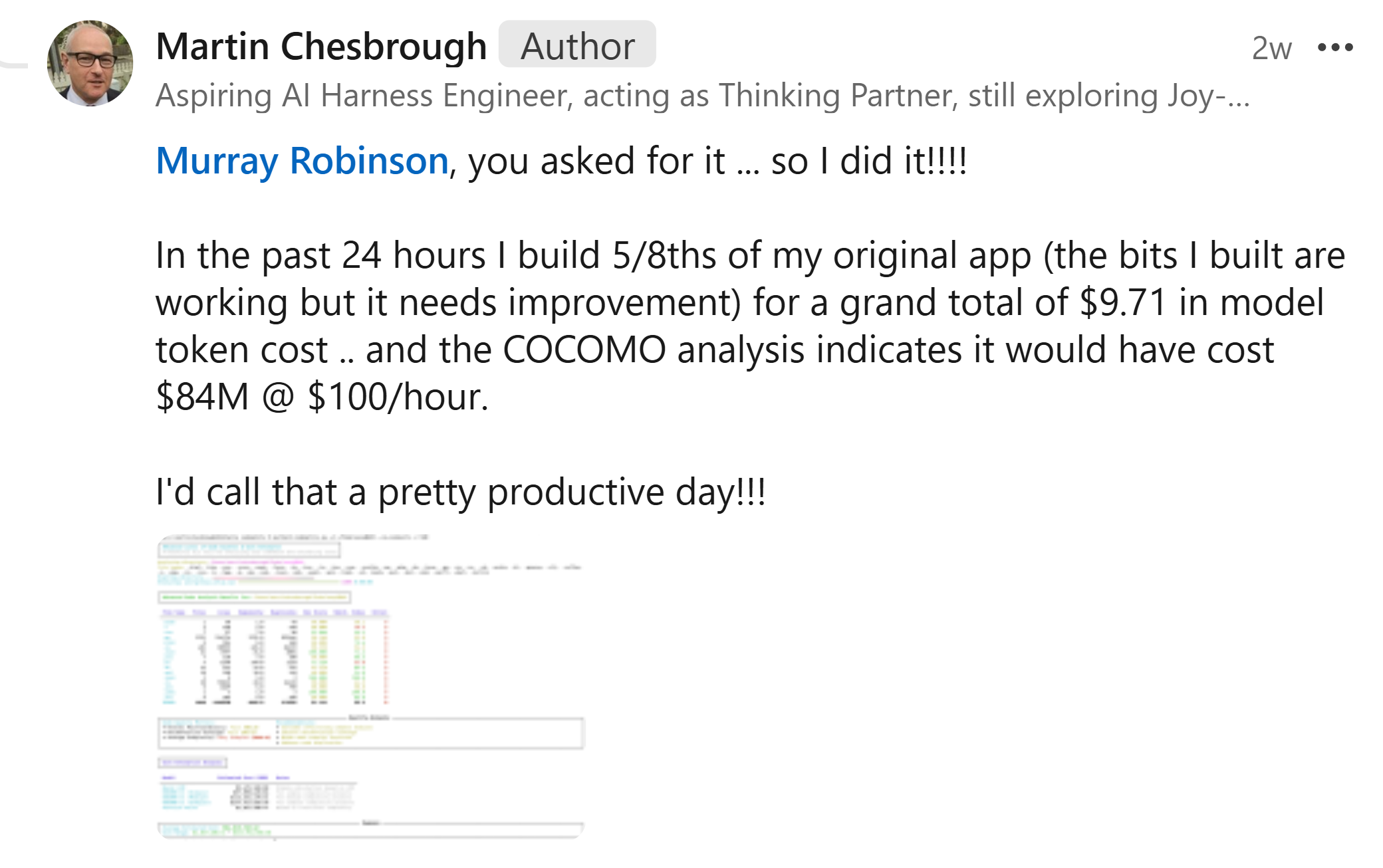
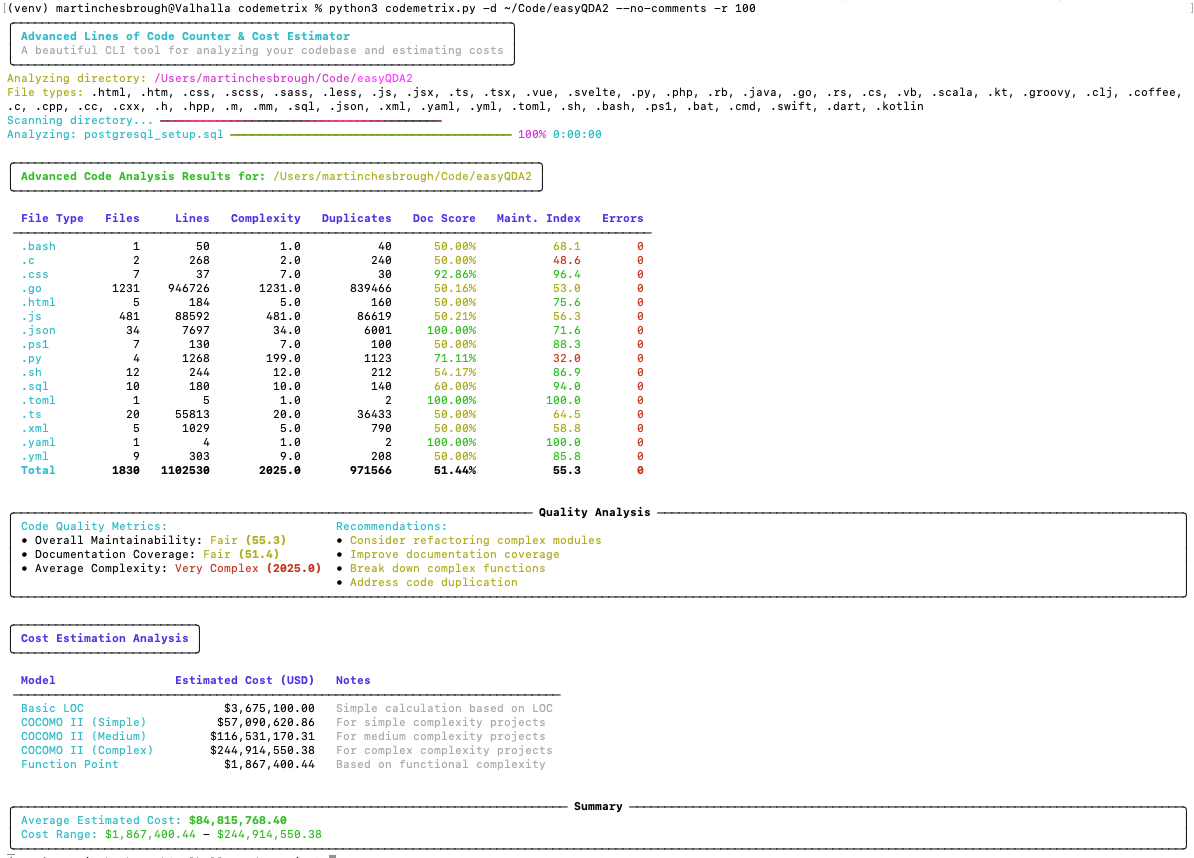
Your recent post reinforced my thoughts on the importance of sub-assemblies. Traditional metrics like COCOMO assume we are building from basic logic and individual lines of code. However, Claude doesn’t “think” in lines of code; it operates at the level of subroutines, modules, and services. COCOMO isn’t stupid, but the premise of manual, low-level coding is stupid when you have access to such sophisticated high-level modules.
To take that further: a huge portion (say, 80%) of ODA development involves simply configuring high-level interfaces and APIs. This is a statistical matching task that plays perfectly to the strengths of an LLM’s logical processing. The massive productivity gains we see with Claude are real, but they are built upon the massive prior investment in component libraries and existing services.
This brings us back to the core of the LinkedIn thread: the need for “thinking time.” We still must perform the heavy cognitive lifting of defining requirements and design. Claude simply automates the “wiring up” of those high-level components—and it’s likely better at mapping fields and reading documentation than a human is.
That leaves the remaining 20% of the work. This is the territory where no pre-existing libraries exist or where requirements haven’t yet been translated into terms an LLM can parse. In this space, true human cognition is still required; AI won’t bridge that gap, and productivity will remain at “normal” levels.
It reminds me of Bill Joy’s comment from the COCOMO era: he noted that in a typical system, only 5% of the code handles the actual core functions, while the other 95% is dedicated to the display. In modern terms, that 95% is now “Claude territory,” while the 5% remains the “thinking territory.”
Of course, this could all just be my own hallucination! 8>}