I Just Did It
The process of developing this site has taken only a few days work (oh how I wish something like this was available when I did my literature search for my PhD!).
Inspiration

In trying to understand how to intervene in ⚡Chaordic situations those who follow the thinking behind Second-Order Cybernetics or Second-Order Systems Thinking recognise the value of different perspectives. Sadly ⚡Perspectives or ⚡Point of View whilst discussed is poorly explained and is never the primary focus of the guidance. This changes here: the architecture is designed around multiple perspectives of the many different thinkers each represented by their 🧑💻Voices. Whilst Dialectic is often discussed it is seldom explained let alone developed as a Guide for Action
Along the Way - A Definition of Systems Thinking
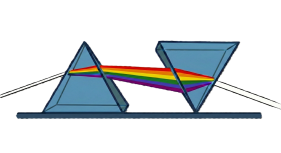
I have always thought of Systems Thinking as the action of using Framing to define a System (that is defining the thing you are thinking about) and Thinking to make sense of what is happening and what might happen. In this representation the process can be depicted as two prisms - the System Framing which generates multiple Perspectives and the Understanding Process (often a dialectic) which makes the various Perspectives coherent. Hence the logo …
Thank to Gemini I produced this image of the process
![]()
Which was further stylised as the logo
![]()
Then finally simplified as the logo
![]() Or the more quizzical logo to reflect the co-authorship of the site materials
Or the more quizzical logo to reflect the co-authorship of the site materials
![]() The basic technical architecture is described in About - Architecture with a pictorial version in Schema. The critical idea which makes everything work is Semantic Normalisation and Content Levelling.
The basic technical architecture is described in About - Architecture with a pictorial version in Schema. The critical idea which makes everything work is Semantic Normalisation and Content Levelling.
Semantic Normalisation and Content Levelling
The AI does the heavy lifting in searching for, summarising and normalising the different ideas from different schools and different thinking. It provides the platform for a democratic transdisciplinary approach. In contrast with the unfettered and comprehensive AI tools such as GeminiAI we use NotebookLM to provide the separate conceptual niches in which the logic of ideas can develop unchallenged and unadulterated by others. The structure of the site comprises largely of the 💬Q&A directories (such as 💬Gists) at the start of each Table of Contents of the Q&A sets is the question used to generate the response presented as
Question posed to the NotebookLM collection of documents
The Excel like access to Content
The revolution that began with the spreadsheet was the ability to access and explore your data. The data part in Excel is simple (just rows and columns) but the capability built on this is terrific (not to mention my personal favourite of the pivot table).
We do not, until now, had the same luxury afforded to text. My contention here is that with the QSet idea we now have the potential for the ‘Excel-like’ operations across a collection of authors/ thinkers and their ideas.
The analysis section of the site contains the interest results of the dialectic process of forming a coherent picture from the various points of view. In our well-understood data world it is the operations we do with Excel variously to mix & match, slice & dice, embrace & extend, compare & contrast our content. It is early days yet but here we start on some of the It is interesting that we can try semi-quantitative queries on non-quantitative data such as common themes including a quantification of the commonly asked aspects
- mix&match - is the basic normalisation of the content how the different author’s depth and vocabulary is refined to a consistent style, length and interpretation (mix) - the difficult to read old books are refreshed and invigorated with no loss of meaning. Cross-source queries can use a common set of search terms (match)
- slice&dice - this is embedded in the site structure the tagging systems - for example Roger-James lets you see everything by that author (slice) and the query language “find similar principles” produces diced selections around common topics (💬)
- embrace&extend - the ‘heavy lifting’ capabilities of NotebookLM can access and summarise massive tomes of text (embrace) and the queries on structure - for example “Can you produce a process map from this material” recasts the source material into a very different form (extend)
- compare&contrast - once you are working with a niche set for different voices with the language aligned through semantic normalisation questions such as “most similar to” (compare) and “most distant from” (contrast)
Prompt
Can you analyse and structure all the questions into common themes including a quantification of the commonly asked aspects?
It is quote remarkable that the AI system provides coherent and accurate answers to such a challenge once the content has been levelled and normalisations. It is also remarkable that we can perform quantitative comparisons on the data and depict relationships and process in diagrams drawn by the system.
Wow!