These sources outline STPrism, a comprehensive framework designed to navigate complex and “chaordic” systems by synthesizing the works of over 50 leading theorists. The material moves away from rigid “Industrial Age” control, instead advocating for systemic inquiry that prioritizes biological metaphors, feedback loops, and emergent behavior. Central to this approach is the “QSet” methodology, which uses AI to normalize and compare divergent perspectives from authors like Ashby, Beer, and Vickers. Practitioners are encouraged to shift from seeking fixed solutions to maintaining dynamic relationships and identifying “leverage points” for intervention. By addressing the “Error of the Third Kind”—solving the wrong problem precisely—the framework provides tools like Rich Pictures and boundary critique to manage uncertainty. Ultimately, the text serves as a guide for transforming unorganized “messes” into manageable, organized complexity through iterative learning and pluralistic thinking.
What is a QSet
A QSet (Question Set) is the fundamental building block and structural core of the STPrism methodology, designed to facilitate the “slice and dice” analysis of complex concepts. It functions as a normalised and levelled digest of an author’s work, created by “re-working” vast amounts of primary source material into a standardised format that is consistent across different thinkers.
Key characteristics and functions of a QSet include:
- Structure and Composition: A QSet is typically a plain text file containing approximately 1,000 words per “Pillar Question” for each author. These “Pillar Questions” establish the specific “line of inquiry” for the research, such as defining an author’s view on “Environment,” “Uncertainty,” or “How-To” guides.
- Semantic Normalisation: The process uses AI to translate an author’s specific jargon or technical shorthand into a “mesh” of ordinary language. This ensures that ideas from different eras or disciplines can be compared on a common basis without the observer being distracted by linguistic “fashions” or buzzword density.
- Parity and Protection of “Weak Signals”: By isolating authors into separate “niches” within NotebookLM, QSets prevent prolific or repetitive writers from statistically “drowning out” brilliant but less voluminous thinkers. This provides parity by volume, ensuring an equal “franchise” for all opinions in the final synthesis.
- “Excel-like” Functionality: Once source materials are normalised into QSets, they enable the analyst to perform operations similar to a spreadsheet—such as mixing and matching, slicing and dicing, or comparing and contrasting—across 50+ diverse voices.
- Epistemological Device: Ultimately, a QSet is not a physical object found in nature but a mental construct or “way of looking” at a document collection to make a “mess” of information tractable.
The current STPrism collection for Systems Thinking includes QSets focused on themes like Distinctions, Gists, Perspectives, and Complexity.
If you would like, I can create a tailored report that deeper explains how these QSets are used to navigate “wicked problems,” or I could generate a quiz to test your understanding of the different authors’ contributions within this framework. Would you like me to do that?
Avoiding the Grey
Can you describe the elements of the STPrism architecture and how it avoids the problem of aggregation (the grey) and preserves distinct opinion
The STPrism (Systems Thinking Prism) architecture is designed as a precision instrument for intellectual inquiry, specifically built to handle multiple perspectives without succumbing to the “destructive mixing and dilution” found in standard AI aggregation.
Core Elements of the STPrism Architecture
- Isolated Niches (Lower Level): The foundation of the system is the deliberate separation of source documents into distinct “niche” containers, typically organized by author (e.g., Stafford Beer vs. James Wilk). This prevents prolific writers or repetitive jargon from statistically overwhelming more subtle but brilliant ideas.
- QSets (Middle Level - Standardization): A QSet (Question Set) is the fundamental building block—a normalized and leveled digest created for each author. The system uses standardized “Pillar Questions” to establish a consistent “line of inquiry” across all isolated niches. This process reduces massive amounts of text to a high-value subset (typically 1,000 words per pillar question per author).
- Semantic Normalisation: The architecture translates an author’s idiosyncratic jargon or technical shorthand into a “mesh” of ordinary, source-independent language. This allows ideas from different disciplines or historical eras (e.g., 1950s science vs. 1990s management) to be compared on a common basis, circumventing “linguistic fashions”.
- Integration and Analysis (Top Level): Only at this final stage are the normalized results from the middle layer compared and contrasted. This is where the human analyst performs “Excel-like” operations—such as “slice and dice”—to derive coherent views rather than statistical averages.
Avoiding the “Problem of Grey” (Aggregation)
The “problem of grey” refers to the tendency of traditional search and general AI models to produce a statistical average or a “murky blue grey” of aggregate consensus. STPrism avoids this through several mechanisms:
- Author Isolation: By keeping “Voices” in separate niches, STPrism prevents “noisy neighbours”—prolific authors who repeat buzzwords—from colonizing the line of inquiry or drowning out “weak signals” from less voluminous thinkers.
- Parity by Volume: The QSet process levels the share of voice for each author. A genius idea expressed in a single paragraph is given an equal “franchise” alongside a voluminous textbook in the final analysis.
- Interrogation over Integration: Instead of asking how authors fit together (which defaults to a homogenized summary), the system forces a confrontation between viewpoints. It explicitly looks for the “Goldilocks position”—ideas close enough to the mainstream to be valid but different enough to bring a new perspective.
- Deferred Merging: Comparison and contrast only happen after individual perspectives have been independently established and normalized, preventing the “destructive mixing” that occurs when diverse views are pooled prematurely.
Preserving Distinct Opinion
STPrism operates on the principle that there is no single “truth” in complex systems; instead, there are multiple viable and conflicting “talking sides”.
- Accommodation over Consensus: The architecture is designed to find an accommodation—a version of a situation that conflicting stakeholders can “live with”—rather than forcing a “grey” average compromise that destroys the unique value of original ideas.
- Protection of “Weak Signals”: It recognizes that in complex situations, progress often comes from the outliers rather than the consensus. Author isolation ensures that these weak signals are not filtered out as “noise” by the statistical probability of the AI’s conceptual mesh.
- Mapping the “Multiversa”: The system accepts the existence of multiple, equally legitimate realities brought forth by different observers. It uses tools like “Team Syntegrity” or “Dialectic Inquiry” to allow these conflicting views to “reverberate” until a higher-order synthesis emerges, preserving the integrity of the original distinct opinions.
The Psychology of STPrism
What are the psychological principles behind why the STPrism approach works
The STPrism approach works by aligning its structural architecture with established psychological principles of human cognition, specifically addressing the inherent limitations in how we perceive and process complexity.
1. Managing Cognitive Load and Bounded Rationality
Human short-term memory is biologically restricted to approximately seven items, a limitation known as “Miller’s Index”. STPrism’s use of QSets functions as a “chunking” mechanism, breaking vast amounts of primary source material into manageable, action-inducing segments that remain within these cognitive limits. By offloading the “mathematics of structure” to structured graphics and normalized text, the approach reduces the “cognitive burden” and frustration experienced when comprehension fails in the face of too many interrelated variables.
2. Overcoming Inattentional Blindness and Pattern Entrainment
Humans naturally suffer from “inattentional blindness”, often failing to see significant anomalies (like the “invisible gorilla”) because they are focused on expected patterns. Past success creates “pattern entrainment”, where experts become blind to new possibilities because their deep knowledge creates a rigid context. STPrism’s architecture of isolated niches prevents prolific or “noisy” authors from statistically drowning out “weak signals” or outliers that do not fit the dominant consensus.
3. Mediating “Spreadthink” and Subjective Bias
In complex situations, groups naturally experience “Spreadthink”, a pathology where individuals hold wildly uncorrelated views on what is important. STPrism handles this by:
- Semantic Normalisation: Translating idiosyncratic jargon into ordinary language removes the “conceptual smokescreen” that triggers emotional or linguistic bias, allowing ideas to be compared on their intrinsic merit.
- Pillar Questions: Using standardized “Pillar Questions” establishes a consistent “line of inquiry”, forcing the observer to look at the same data through different lenses simultaneously to reduce the risk of “solving the wrong problem precisely”.
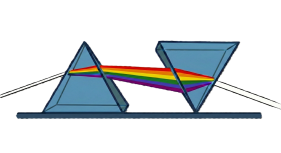
4. Exploiting “Binocular Vision” for Depth Perception
The approach relies on Gregory Bateson’s principle of “Double Description” (or binocular vision). Just as two eyes provide a “bonus of depth” that a single eye cannot achieve, STPrism combines distinct, non-equivalent descriptions of a situation to generate a higher order of insight. By deliberately maintaining the “otherness” of conflicting perspectives rather than forcing a “grey” average consensus, the architecture allows for the perception of relationships that are invisible from a single vantage point.
5. Transitioning from “Reflexive” to “Reflective” Thought
The STPrism methodology, specifically through the “kneading” of prompts, moves the analyst from reflexive thinking (first-fit pattern matching based on past experience) to reflective inquiry. It acts as an “intellectual amplifier” or a “ReMemex”, reaching back to trigger principles and perspectives that have slipped below the conscious threshold due to modern information overload. This process encourages “epistemic modesty”, requiring the investigator to acknowledge that their current mental models are provisional “useful fictions” rather than objective reality.
6. Value-Driven Perception (Gumption and Quality)
The approach acknowledges that human perception is not value-neutral but is filtered through “appreciative settings”—the readiness to see and value certain things while ignoring others. By using Robert Pirsig’s concept of “stuckness” as a starting point for true understanding, STPrism helps analysts identify “gumption traps” like value rigidity. This psychological preparation ensures the investigator is not just looking for a “technical fix” but is identifying the deep structure of values and purpose that makes a system meaningful.
Semantic Normalisation
What is semantic normalisation why is it important
Semantic normalisation is a foundational process within the STPrism architecture that involves re-working and translating an author’s idiosyncratic jargon or technical shorthand into a “mesh” of ordinary, source-independent language. By using standardized “Pillar Questions” to extract these normalized digests—known as QSets—the methodology ensures that diverse perspectives are leveled to a consistent style, length, and interpretive depth.
Why Semantic Normalisation is Important
The sources highlight several critical reasons why this process is essential for navigating complex “messes”:
- Circumventing “Linguistic Fashions”: Academic and technical terminology often follows trends that change over decades or vary wildly between disciplines. Normalisation allows the system to identify the same underlying concepts described by writers in different eras (e.g., the 1940s vs. the 1990s) without the observer being trapped by outdated vocabulary.
- Enabling “Excel-like” Operations: Once source materials are semantically aligned, they function like rows and columns in a spreadsheet. This allows an analyst to perform operations such as “slice and dice,” “mix and match,” or “compare and contrast” across 50+ diverse voices on a common basis.
- Protecting “Weak Signals” from “Noisy Neighbors”: Prolific authors who repeat buzzwords can statistically “drown out” brilliant thinkers who may have expressed a genius idea in only a single paragraph. Normalisation provides parity by volume, ensuring that every unique perspective has an equal “franchise” in the final synthesis.
- Mitigating “Source Pollution”: In a standard search, a dominant term (like “Cynefin”) can “carpet bomb” a query, obscuring more subtle signals. Normalisation isolates authors into separate “niches” before integration, preventing the destructive mixing and dilution that occurs when diverse views are pooled prematurely.
- Refreshing “Old Books”: It allows valuable insights trapped in “dusty” or difficult-to-read foundational texts to be invigorated and mapped onto modern challenges without loss of their core meaning.
- Creating a Uniform API for Knowledge: Effectively, the process provides a uniform application programming interface for thousands of pages of text, allowing the analyst to use ordinary language search terms to retrieve relevant content across the entire library.
In essence, semantic normalisation transforms a fragmented “babel” of specialized disciplines into a precision instrument for intellectual inquiry, allowing human intelligence to be augmented by the AI’s ability to recognize patterns across vast conceptual distances.
Pillar Questions
What is the role of Pillar Questions in semantic normalisation?
In the STPrism architecture, Pillar Questions serve as the structural engine for semantic normalisation, acting as the “line of inquiry” that transforms raw, idiosyncratic source material into a comparable and standardised format.
Their role in this process is defined by several key functions:
1. Establishing the “Line of Inquiry”
Pillar Questions define the primary use and purpose of the source data. They act as a directed content search, identifying and extracting only the relevant aspects of an author’s work to create a focused digest. Setting these questions is considered an essential “craft skill” requiring subject matter expertise; if inappropriate questions are chosen, the resulting QSet may be useless or misleading.
2. Circumventing Jargon and Technical Shorthand
Because these questions operate within the Large Language Model’s (LLM) conceptual mesh, they can bypass an author’s specific technical shorthand. This is the core of semantic normalisation: content retrieval is based on underlying concepts (a broad “general language”) rather than the narrow, reserved jargon typical of traditional search engines. This allows the system to find common ground between different academic disciplines that may use different words for the same fundamental idea.
3. Neutralising “Linguistic Fashions”
Academic and professional terminology often follows “fashions” or trends that change over decades. Pillar Questions allow the system to avoid this “trap” by identifying the same underlying phenomenon described by writers in different eras. This enables the system to “level” the ideas of foundational pioneers with contemporary writers, making them comparable on a consistent basis.
4. Providing Weighting Parameters (“Kneading”)
Pillar Questions function as weighting parameters that “knead” the source information. They align the underlying content along specific axes of thinking, creating a bespoke lens through which the material is viewed. This process ensures that the resulting output is not a mere statistical average but a targeted extraction of the author’s perspective on a specific theme, such as “Environment,” “Uncertainty,” or “Complexity”.
5. Enabling “Excel-like” Operations
By normalising the style, length, and interpretive depth of every author’s contribution through these standard questions, the system creates a uniform application programming interface (API) for the entire library. Once the content is levelled, an analyst can perform operations similar to a spreadsheet—such as “slice and dice” or “compare and contrast”—across dozens of diverse voices simultaneously.