In One Diagram
Quote
🚧Temporary Fix: I start with a humble apology #Bug On the website you will see a picture followed by an error message. This is due to a bug in Quartz which gets upset with some of the Mermaid diagrams. They work perfectly in Obsidian and Perlite. Here the picture is so important I needed to provide a hack until the Quartz fix arrives. Sorry!
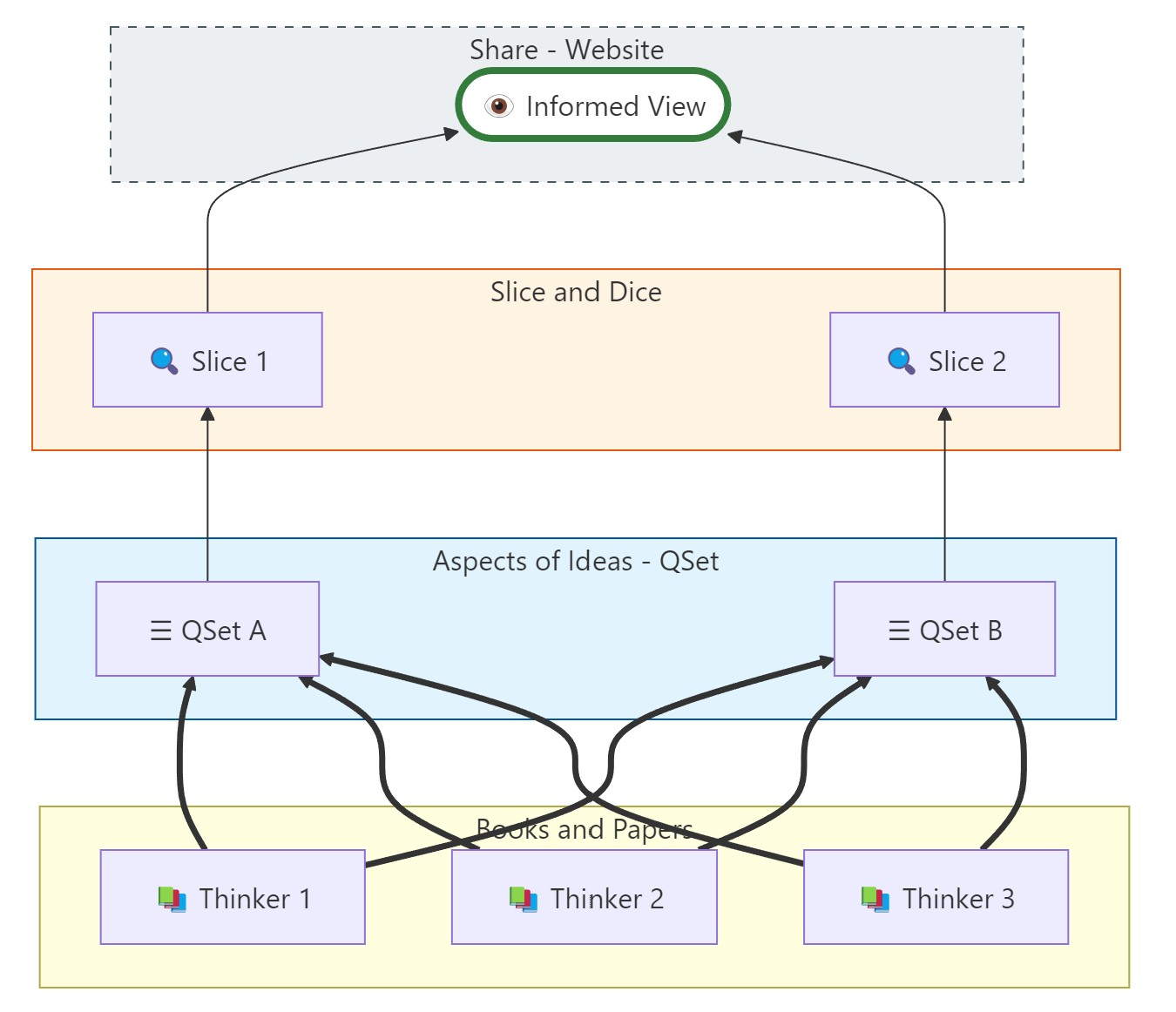
graph BT Box 3: Slice and Dice subgraph Slice_Dice_Box ["Slice and Dice"] direction LR Q1["🔍 Slice 1"] Q2["🔍 Slice 2"] end Box 1: Books and Papers (Bottom) subgraph Books_Box ["Books and Papers"] direction LR B1["📚 Thinker 1"] B2["📚 Thinker 2"] B3["📚 Thinker 3"] end The Mesh: Every Thinker connects to every QSet B1 ==> S1 B1 ==> S2 B2 ==> S1 B2 ==> S2 B3 ==> S1 B3 ==> S2 Convergence: All Slices terminate at the Informed View Q1 --> IV Q2 --> IV %% Styling style Website_Box fill:#eceff1,stroke:#455a64,stroke-dasharray: 5 5 style Slice_Dice_Box fill:#fff3e0,stroke:#e65100 style QSets_Box fill:#e1f5fe,stroke:#01579b style IV fill:#ffffff,stroke:#2e7d32,stroke-width:4px
The Core Concept: Semantic Normalisation The fundamental challenge addressed by this system is to avoid the “destructive mixing and dilution” that occurs when diverse perspectives are combined without care. In the search paradigm ‘all roads lead to Rome’ and it is selection of the dominant term(s).
In challenges requiring different perspectives the onus is on parity, no one thing is right and many things are viable from which some are preferred.
To solve this, the system uses NotebookLM to “re-work” source materials into QSets—standardized digests that retain the unique voice and core concepts of each author. This process is defined as Semantic Normalisation and Content Levelling, which ensures that ideas from different thinkers in different forms and different expressions are kept isolated and levelled to a consistent format.
Implementation & Architecture The system is built on Obsidian, a local notebook chosen for its ability to manage the website structure and manage “automated navigation such as hyperlinks”. The technical structure is detailed in About - Architecture and visualized in the Schema.
• Data Ingestion: Documents are searched and selected using Recoll and prepared for ingestion (see Constructors Guide).
• Analysis: NotebookLM processes these collections to produce specific outputs, such as the QSets - Perspectives in Practice which form the basis of the analysis.
• Publication: The site is published using tools like Perlite or Quartz, which preserve the complex linking structure (see UI Cheat Sheet).
Navigating the Content The “re-worked” content allows for “Excel-like” operations—such as “slice & dice”—across the different perspectives.
• Voices: You can explore individual authors (e.g., Robert Pirsig).
• Analysis: You can view synthesized comparisons, such as Concepts - Structural Polarities or Cross-tab of the different approaches.
• Guidance: For a practical introduction, the Walk Through provides a step-by-step guide, while 🤯Rogers WOW List highlights significant analytical insights.
Important Considerations
• Pollution: Great care must be taken during the “re-working” phase to avoid Pollution, where terms from one author (such as Cynefin) can overwhelm the more subtly presented ideas of another.
• Copyright: The system operates under “fair dealing” principles, as detailed in Content and Copyright and Copyright - Fair Use in UK Law.
To prove the point this is the AI reworked overview from my Quick-Start documents.